Structured data exchange
Minyu handles imports and exports at the level of the full data model—not isolated CSV files—so large updates, migrations, and corrections can be performed without breaking relationships or compromising consistency. Instead of forcing operators to manually maintain identifiers, apply business logic, or untangle dependencies, Minyu processes data structurally and validates it against the configured schema.
Bulk operations never rely on procedural scripts or hand-crafted tooling. They operate on full tables, maintain referential integrity, detect row-level problems in isolation, and produce detailed reports for review before anything touches live data.
Model-driven imports at scale
Bulk Import loads large volumes of data into Minyu using a single ZIP file containing one CSV file per table. File names map directly to table API names, ensuring predictable routing of rows into the correct tables. Many-to-many relations are supported through dedicated linking files, making it possible to reconstruct even the most complex relational structures in one operation.
The import process is divided into four stages:
-
Upload & structural validation The ZIP file is validated against schema structure, file naming, and column requirements.
-
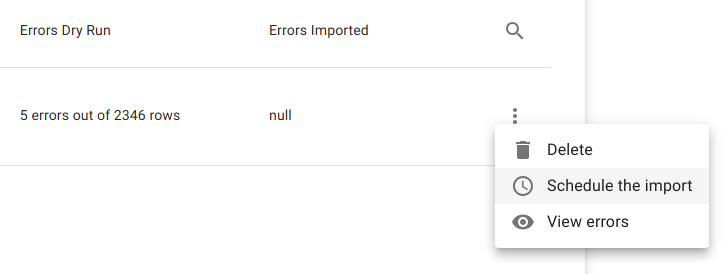
Dry run A full execution is simulated on temporary tables. All type conversions, identifier lookups, and relation resolutions are performed without modifying live data.
-
Error review Errors are produced per row and per file. Operators can download the error set and correct data before running the import agains live data.
-
Scheduled execution Once approved, the import runs as a batch job against live data.
Only one import is active at a time, ensuring system integrity and avoiding competing bulk operations.
Structural safety without write-rule evaluation
Bulk imports bypass write rules entirely. This is intentional.
Write rules are designed for interactive workflows, where each user-driven change is validated in real time. Applying the same rules to a million-row import would be unpredictable, slow, and in many cases logically incorrect (because rules often describe operational constraints, not data migration policies).
Instead, Bulk Import enforces:
- schema constraints
- valid column types
- correct identifiers
- referential integrity
- non-overlapping relation updates
- valid many-to-many link edges
Everything else—including business-level write rules—remains inactive during import execution.
This ensures that large dataset operations are deterministic, high-performance, and structurally correct. All changes still flow into the audit log, and business rules resume immediately after the import completes.
Point-in-time exports with enforced read rules
Exports in Minyu are the mirror image of imports:
- Imports bypass write rules for performance
- Exports enforce read rules for security
A standard export represents a point-in-time snapshot of the system. It is evaluated in the context of the requesting user and always respects read rules, ensuring that:
- restricted rows are excluded
- related data is filtered consistently
- column ordering and relations follow the export definition
- no cached or stale data is used
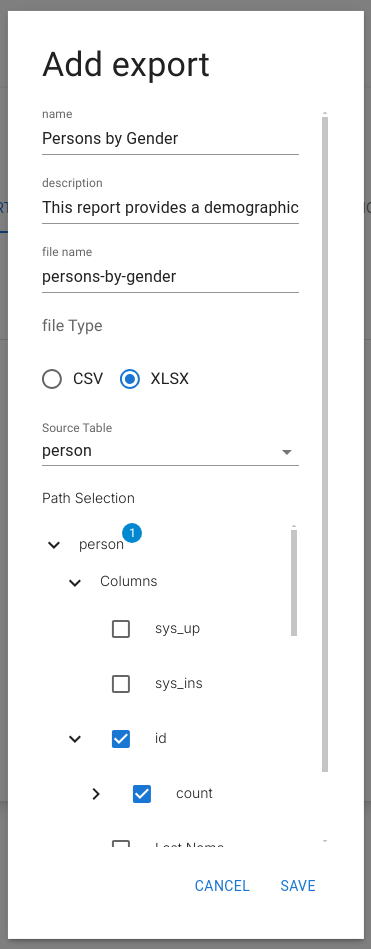
Exports may include data from the source table and any number of related tables. Relation traversal follows the schema and mirrors the structure exposed by the API.
Supported output formats:
- CSV
- Excel
All values—including nulls—are preserved exactly as stored.
GDPR exports
GDPR data export is a separate, regulated module and intentionally operates outside the normal export mechanism.
For legal reasons, GDPR exports:
- bypass read rules entirely
- export the full, predefined personal-data scope
- include related data, audit history, and access logs
- are available only to users with an explicitly assigned high-trust role
Although the output format may look similar, GDPR export is not a technical export variant—it is a compliance action governed by its own configuration, execution flow, and audit requirements.
Summary
Minyu’s bulk data exchange is designed for real-world operational work: migrating legacy systems, loading large external datasets, or performing wide-ranging corrections without risking relational integrity.
- Imports operate structurally, bypass write rules, and isolate row-level errors
- Exports apply full read-rule enforcement and reflect the current model
- ZIP-based formats simplify repeatability and reproducibility
- Many-to-many structures are fully supported
- All operations are auditable, predictable, and aligned with the schema
The result is a safe, high-throughput mechanism for moving data in and out of Minyu without ever compromising consistency.
→ Read more: Bulk import, Data export