Processing — how the system transforms data

Processing explains what the system does internally once something has happened.
It does not describe user interaction.
It does not describe rules or permissions.
It does not describe data movement between systems.
Processing begins after input has occurred and describes how the system produces new data or new state from what it already knows.
Scope — what counts as processing

The result of processing is any data the system produces by itself.
Processing is the internal work the system performs to produce that result — such as evaluating conditions, calculating values, changing state, or accumulating history.
Any event that causes this work to start is not part of processing. Triggers explain why processing runs; processing describes what the system does once it runs.
If a value was entered directly by a user, it belongs to Interaction.
If a value arrived fully formed from another system, it belongs to Integration.
If the system had to actively evaluate, calculate, or transform existing information to arrive at a result, that work is Processing.
Processing is always secondary.
It happens because something else already occurred, but it is defined by the work itself — not by what triggered it.
All processing is one of three transformation types
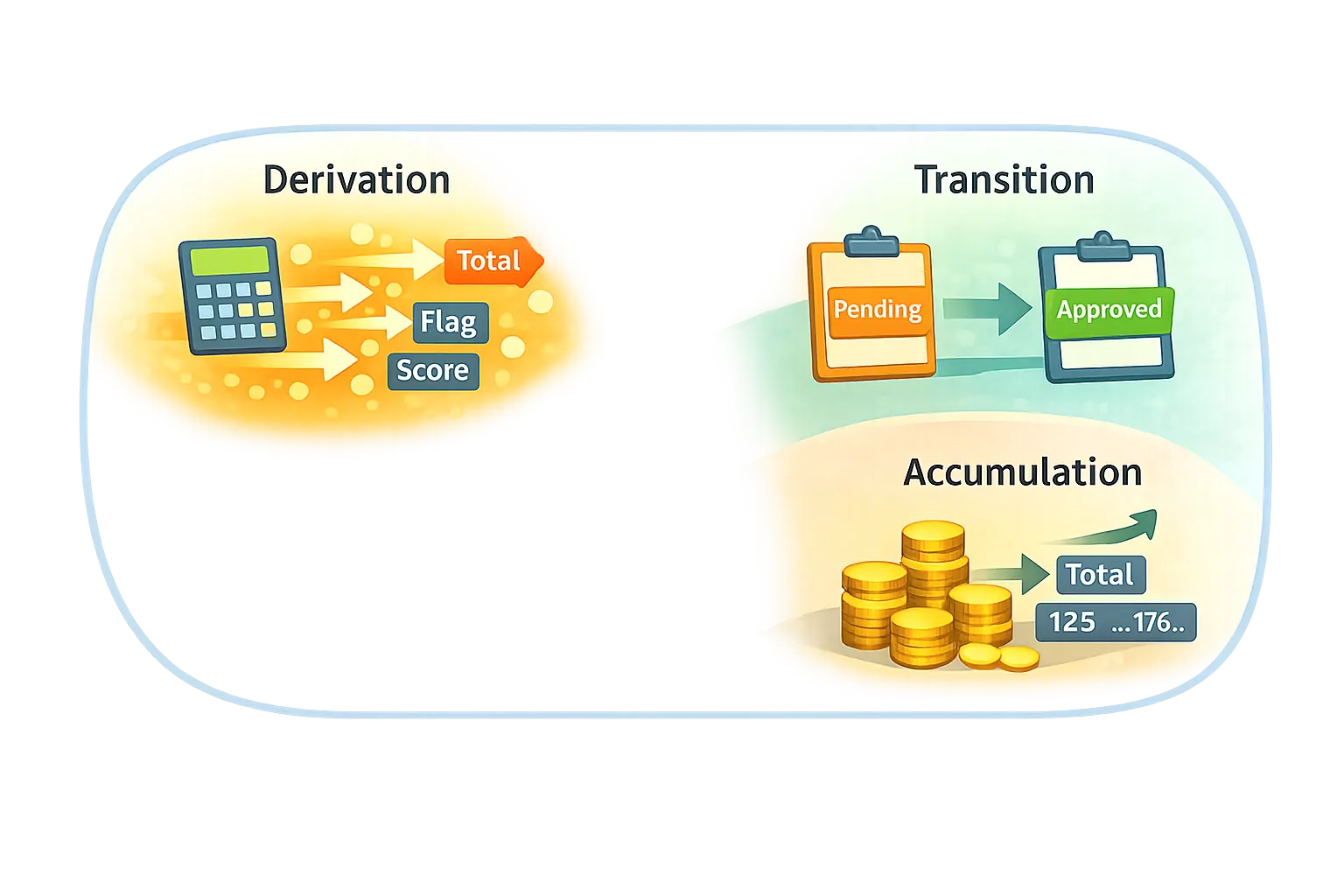
Every piece of processing falls into exactly one of the following categories.
Derivation — calculating new values
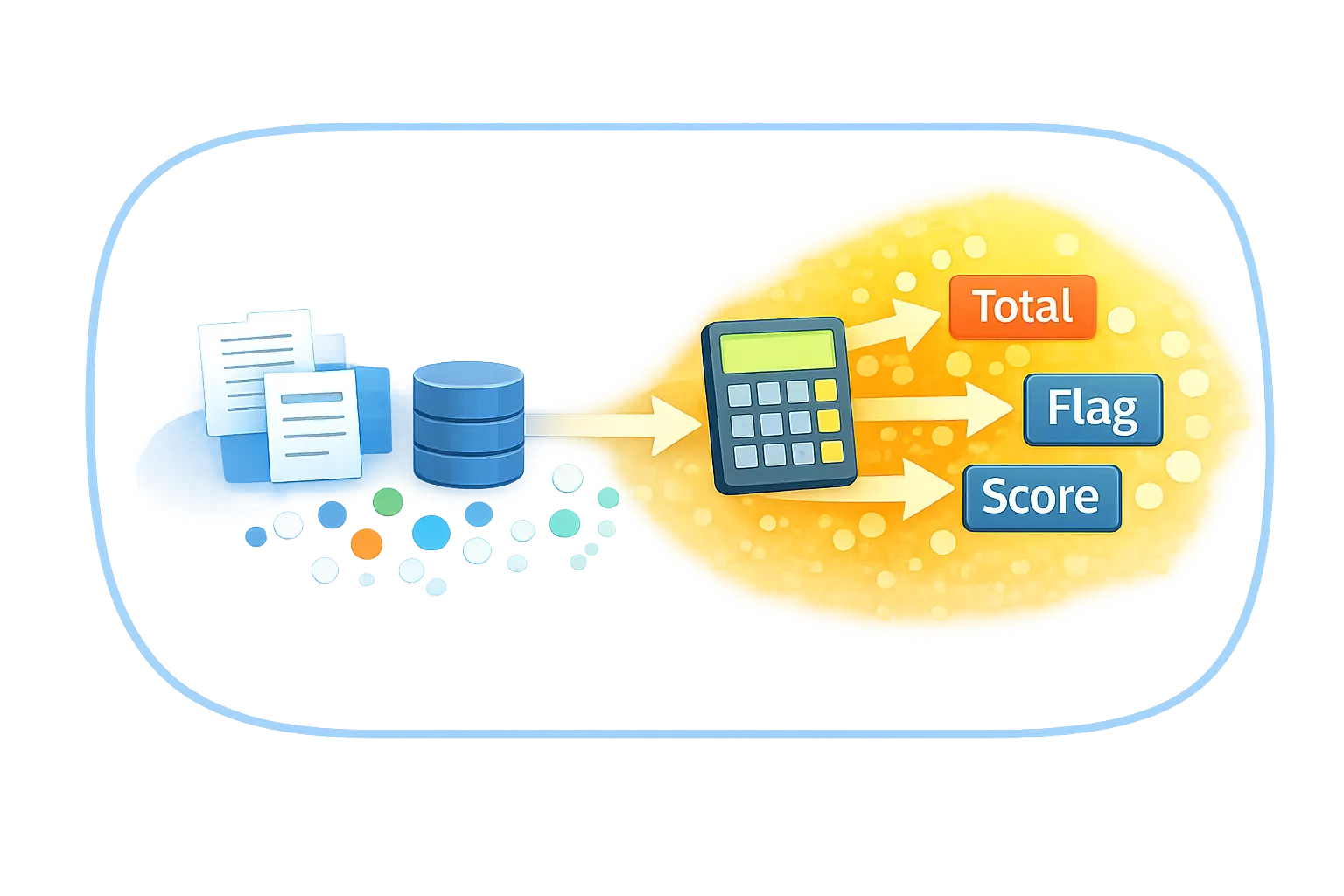
Derivation is processing where the system calculates new values from existing information.
Common examples include totals, flags, computed prices, or derived indicators.
The guiding test is:
“If we delete this value, can the system recompute it?”
If the answer is yes, the value is derived.
Derived values do not carry history.
They represent the result of applying logic to current data.
Transition — changing state
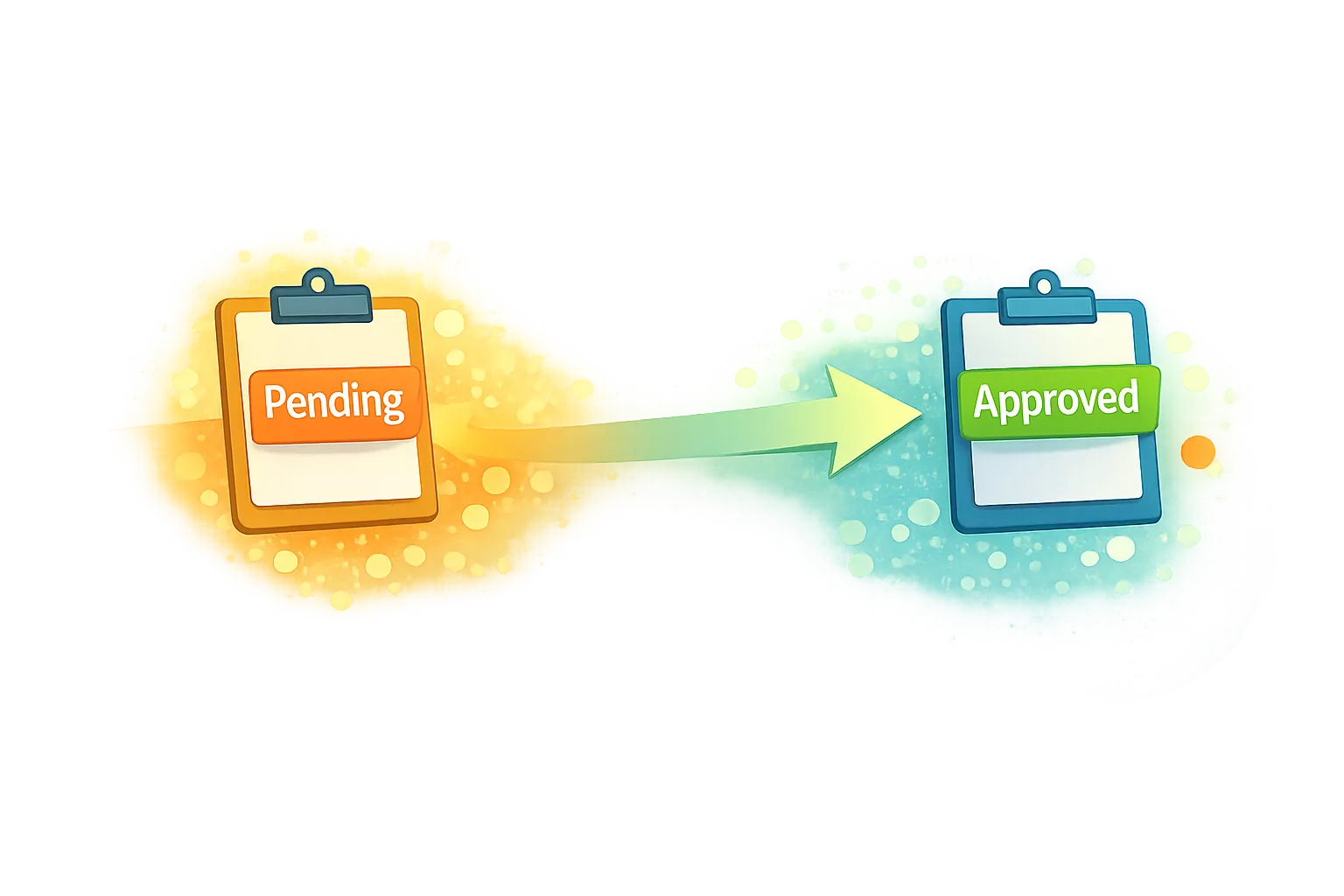
Transition is processing where the system changes state.
Typical examples include an order becoming shipped or an invoice becoming paid.
The guiding test is:
“Does this represent a point of no return?”
If reversing the change would require special handling, a transition has occurred.
Transitions mark commitment.
Once crossed, the system must behave differently.
Accumulation — building values over time
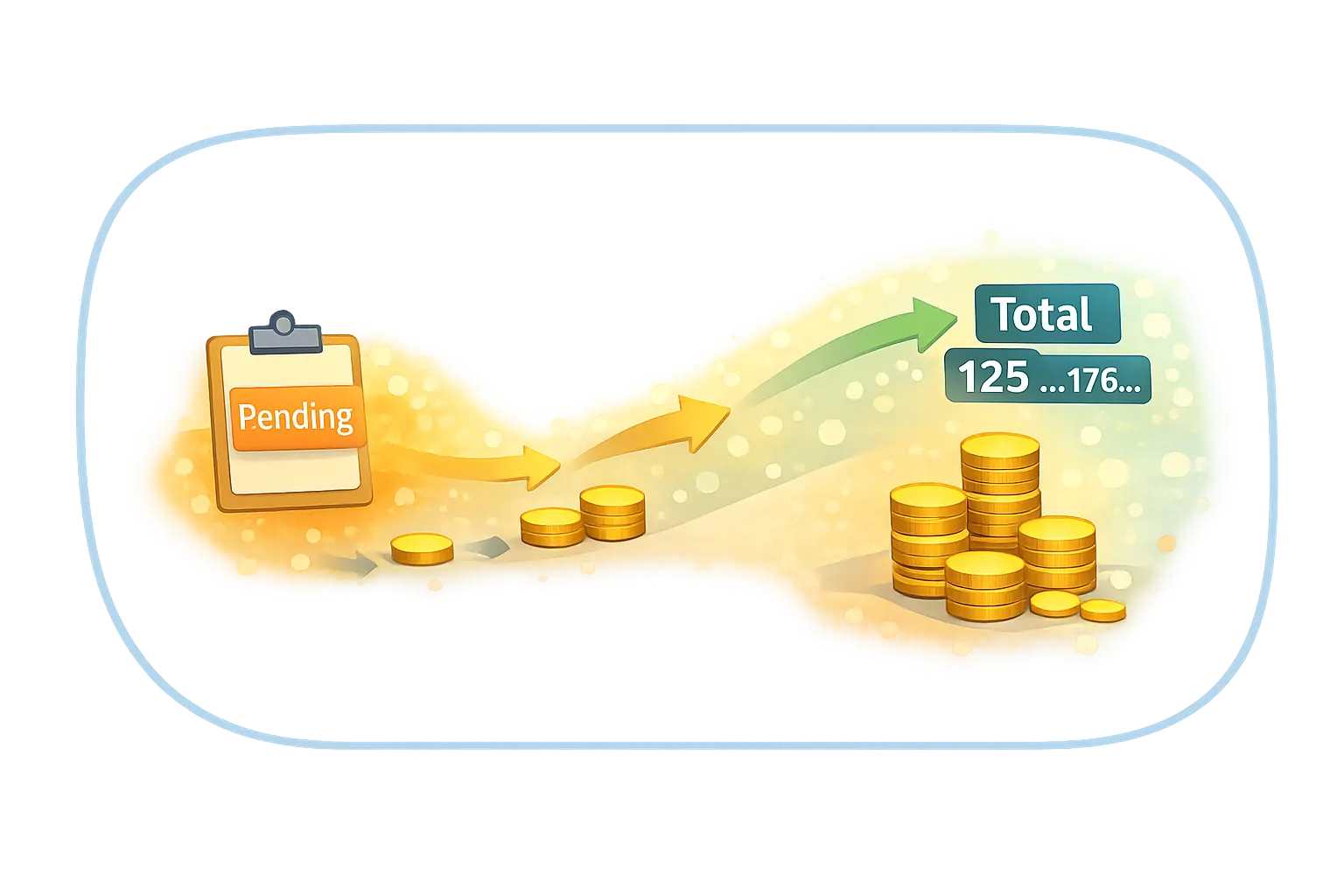
Accumulation is processing where values are built up over time.
Examples include balances, counters, inventory levels, usage totals, or quotas.
The guiding test is:
“Do we need the past to know the correct value?”
If the answer is yes, the value is accumulated.
Accumulation is not recalculation.
It works by applying deltas, not by recomputing from scratch.
The current value represents a history, not just the present state.
Order matters.
Applying the same changes in a different order may produce a different result.
Accumulation may be replayable or irreversible. When underlying events are gone, accumulated values cannot be verified or rebuilt.
Accumulation often looks simple, but errors tend to compound over time.
Triggers — why processing runs
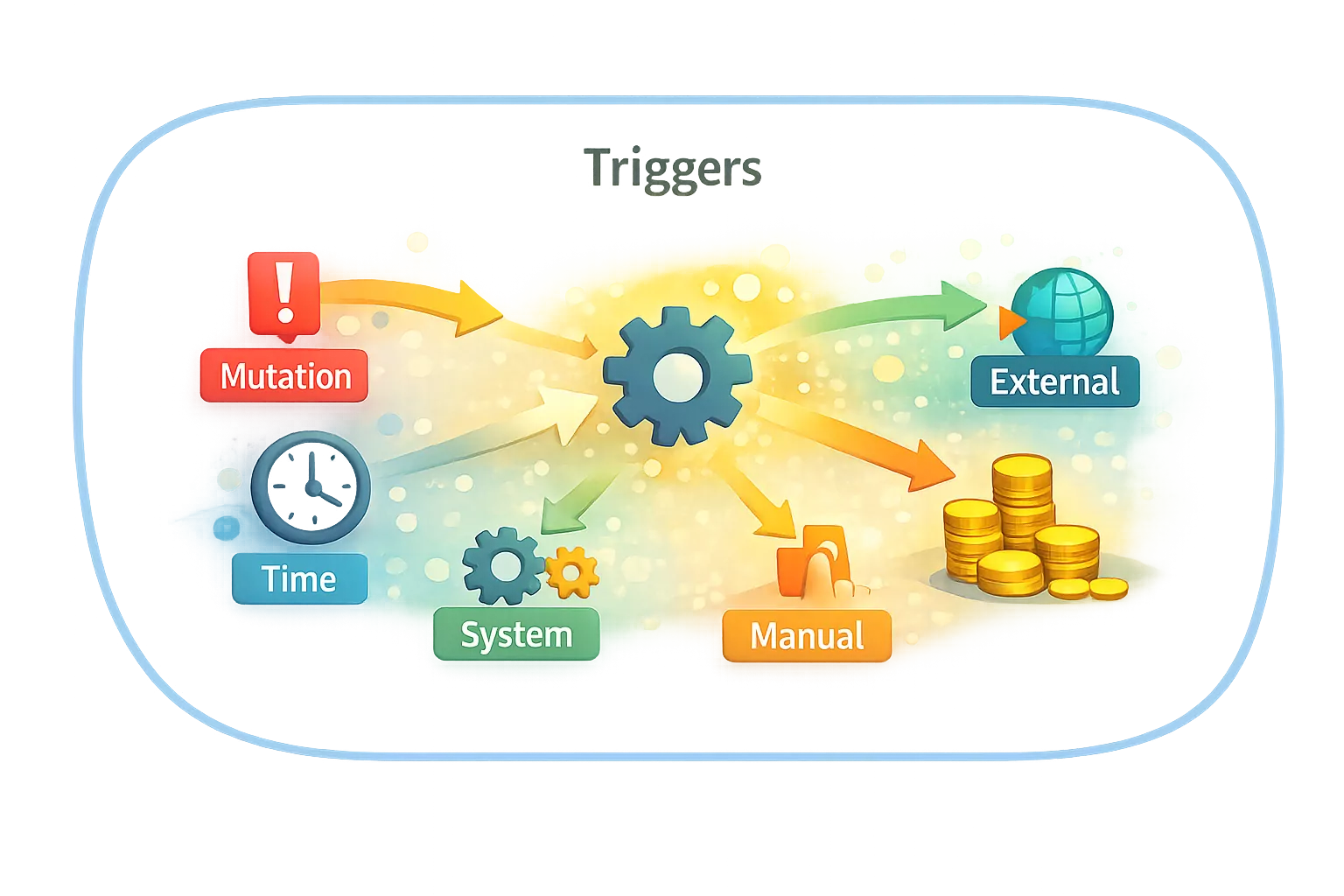
Processing does not run randomly.
It always starts because of exactly one trigger.
Mutation — data changed
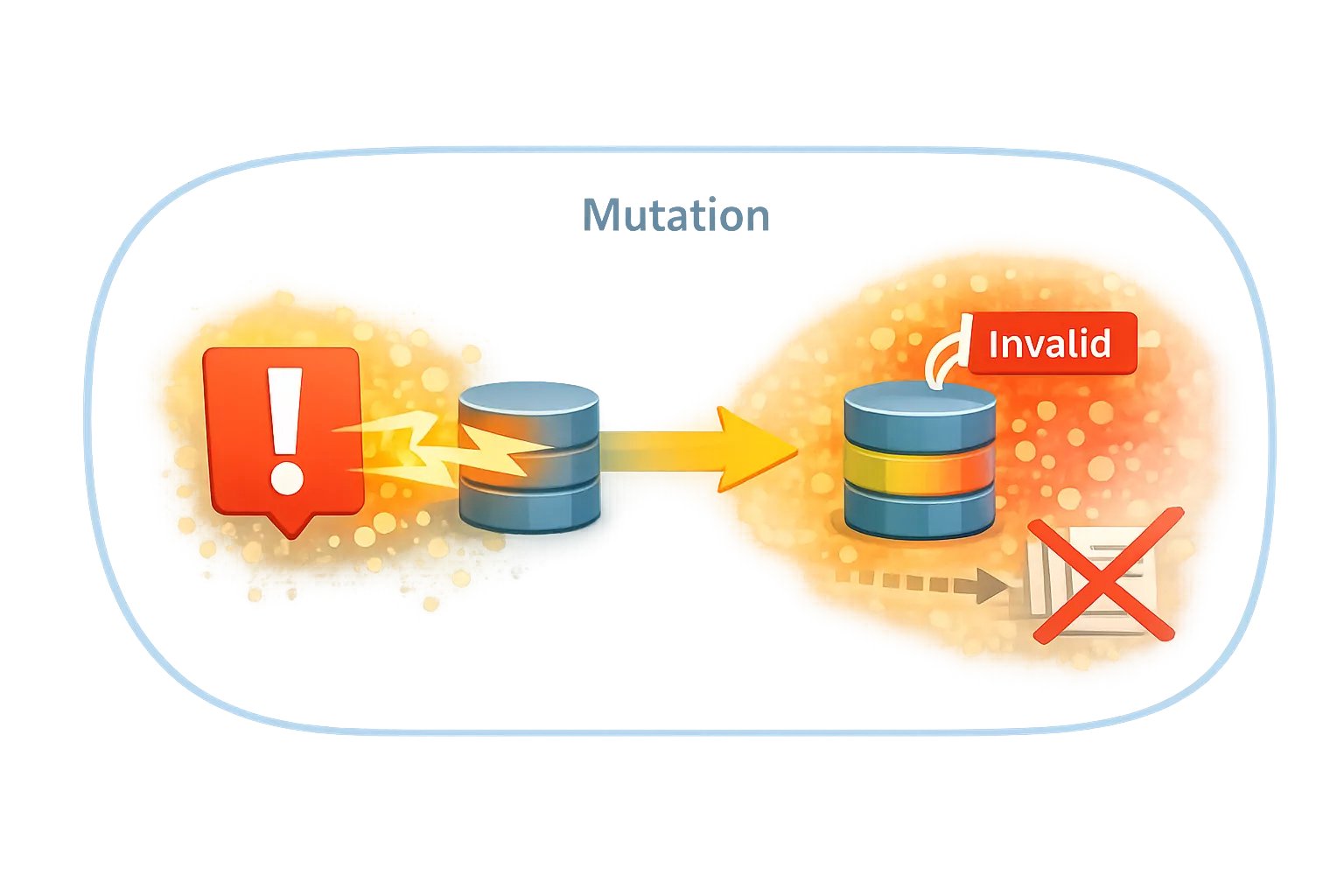
Mutation-triggered processing starts because data was changed.
The guiding test is:
Did processing start because something changed?
A value was updated.
A record was created.
A state transitioned.
Processing reacts to the mutation.
Time — a time boundary was reached

Time-triggered processing starts because a time condition was met.
The guiding test is:
Did processing start because time advanced?
No data changed.
No user acted.
A time boundary was crossed.
If a meaningful time condition exists, the trigger is Time.
System — self-triggered execution

System-triggered processing starts because the system decides to run itself.
It does not react to data changes.
It does not follow a meaningful business time condition.
It does not require a user action.
While the system is running, it repeatedly executes the same logic, evaluating the current situation and raising an event only if a condition is violated. The processing would still run even if nothing has changed since the previous run.
Delays or pauses may be used to avoid constant execution, but time is only a pacing mechanism. The system would behave the same if triggered on startup, in a loop, or at irregular intervals.
The guiding test is:
Would this run again even if nothing changed and no external event occurred?
If yes, the trigger is System.
Manual — user-initiated execution
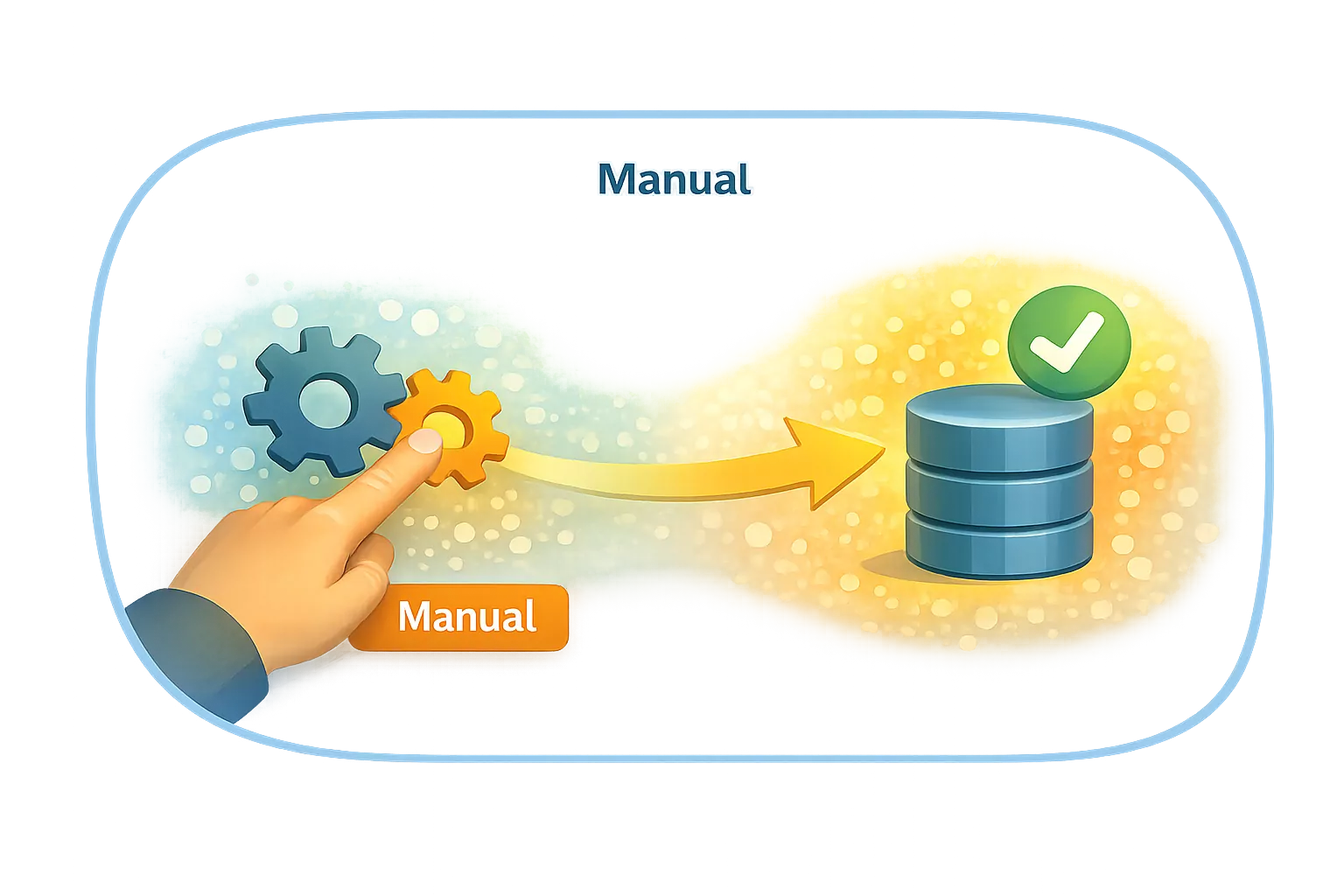
Manual-triggered processing starts because a person explicitly initiates it.
It does not depend on data changes.
It does not depend on time.
It does not run automatically.
The guiding test is:
Would this ever run unless a person explicitly asked for it?
If not, the trigger is Manual.
External — something outside the system acted
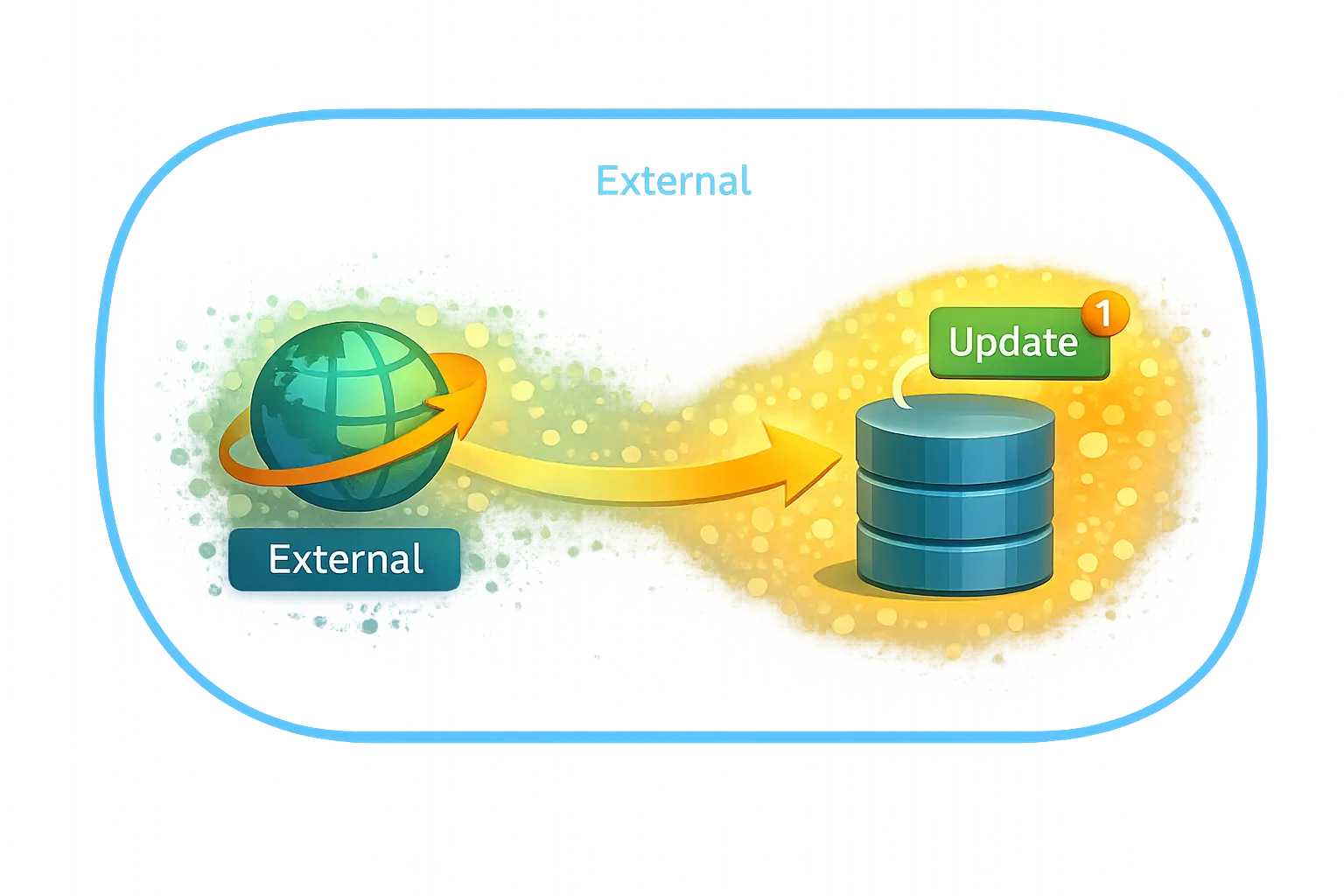
External-triggered processing starts because something outside the system initiated it.
The guiding test is:
Could this have happened without an external system acting?
If not, the trigger is External.
Discipline rules
Some distinctions must remain strict.
State is never a trigger — it is only a condition.
If time is involved in a meaningful way, the trigger is Time.
Order alone never triggers processing; it only affects how processing behaves once triggered.
Breaking these rules causes models to collapse into ambiguity.
Why this model is intentionally limited
This model does not attempt to: - explain implementations - cover every edge case - debug distributed systems
A simple model that can be reasoned about is more useful than a complete model that cannot.
Final synthesis
A business system defines information and meaning, enables human interaction, enforces rules, integrates across boundaries, and internally processes data by deriving values, transitioning state, or accumulating history — triggered by mutation, time, system execution, manual action, or external action.
If you can classify a problem into one of these areas, the system is understandable.
Everything else is secondary.